
Cách thay đổi tác nhân người dùng trong Chrome, Edge, Safari và Firefox
Đọc tiếp


Làm thế nào để tối ưu hóa ngân sách thu thập dữ liệu của bạn? Trong hướng dẫn này, hãy khám phá những mẹo hàng đầu giúp trang web của bạn có thể thu thập dữ liệu nhiều nhất có thể cho SEO.
Ngân sách thu thập dữ liệu là một khái niệm SEO quan trọng đối với các trang web lớn có hàng triệu trang hoặc các trang web vừa có vài nghìn trang thay đổi hàng ngày.
Một ví dụ về trang web có hàng triệu trang là eBay.com, còn các trang web có hàng chục nghìn trang được cập nhật thường xuyên là các trang web đánh giá và xếp hạng của người dùng tương tự như Gamespot.com.
Có rất nhiều nhiệm vụ và vấn đề mà một chuyên gia SEO phải cân nhắc đến nỗi việc thu thập thông tin thường bị gác lại.
Nhưng ngân sách thu thập dữ liệu có thể và nên được tối ưu hóa.
Trong bài viết này, bạn sẽ học được:
Làm thế nào để cải thiện ngân sách thu thập thông tin của bạn trong quá trình này.
Xem xét những thay đổi về khái niệm ngân sách thu thập dữ liệu trong vài năm qua.
( Lưu ý : Nếu bạn có một trang web chỉ có vài trăm trang và các trang không được lập chỉ mục, chúng tôi khuyên bạn nên đọc bài viết của chúng tôi về các sự cố phổ biến gây ra sự cố lập chỉ mục , vì chắc chắn không phải do ngân sách thu thập dữ liệu.)
Ngân sách thu thập dữ liệu đề cập đến số trang mà trình thu thập dữ liệu của công cụ tìm kiếm (tức là nhện và bot) truy cập trong một khung thời gian nhất định.
Có một số cân nhắc nhất định khi lập ngân sách thu thập dữ liệu, chẳng hạn như sự cân bằng tạm thời giữa nỗ lực của Googlebot nhằm không làm quá tải máy chủ của bạn và mong muốn thu thập dữ liệu chung của Google về tên miền của bạn.
Tối ưu hóa ngân sách thu thập dữ liệu là một loạt các bước bạn có thể thực hiện để tăng hiệu quả và tốc độ mà bot của công cụ tìm kiếm truy cập vào trang của bạn.
Thu thập dữ liệu là bước đầu tiên để xuất hiện trong tìm kiếm. Nếu không được thu thập dữ liệu, các trang mới và cập nhật trang sẽ không được thêm vào chỉ mục của công cụ tìm kiếm.
Càng nhiều trình thu thập thông tin truy cập vào trang của bạn, các bản cập nhật và trang mới sẽ xuất hiện trong chỉ mục càng nhanh. Do đó, các nỗ lực tối ưu hóa của bạn sẽ mất ít thời gian hơn để có hiệu lực và bắt đầu ảnh hưởng đến thứ hạng của bạn.
Chỉ mục của Google chứa hàng trăm tỷ trang và đang tăng lên mỗi ngày. Các công cụ tìm kiếm phải mất chi phí để thu thập từng URL và với số lượng trang web ngày càng tăng, họ muốn giảm chi phí tính toán và lưu trữ bằng cách giảm tốc độ thu thập và lập chỉ mục URL .
Ngoài ra, việc giảm phát thải carbon để ứng phó với biến đổi khí hậu cũng ngày càng cấp thiết và Google có chiến lược dài hạn nhằm cải thiện tính bền vững và giảm phát thải carbon .
Những ưu tiên này có thể khiến các trang web khó được thu thập dữ liệu hiệu quả trong tương lai. Mặc dù ngân sách thu thập dữ liệu không phải là thứ bạn cần lo lắng đối với các trang web nhỏ có vài trăm trang, nhưng quản lý tài nguyên lại trở thành vấn đề quan trọng đối với các trang web lớn. Tối ưu hóa ngân sách thu thập dữ liệu có nghĩa là để Google thu thập dữ liệu trang web của bạn bằng cách sử dụng càng ít tài nguyên càng tốt.
Vì vậy, hãy cùng thảo luận về cách bạn có thể tối ưu hóa ngân sách thu thập thông tin của mình trong thế giới ngày nay.
Bạn có thể ngạc nhiên, nhưng Google đã xác nhận rằng việc không cho phép URL sẽ không ảnh hưởng đến ngân sách thu thập dữ liệu của bạn. Điều này có nghĩa là Google vẫn sẽ thu thập dữ liệu trang web của bạn với cùng tốc độ. Vậy tại sao chúng ta lại thảo luận về điều này ở đây?
Vâng, nếu bạn không cho phép các URL không quan trọng, về cơ bản bạn đang yêu cầu Google thu thập dữ liệu các phần hữu ích trên trang web của bạn với tốc độ cao hơn.
Ví dụ, nếu trang web của bạn có tính năng tìm kiếm nội bộ với các tham số truy vấn như /?q=google, Google sẽ thu thập các URL này nếu chúng được liên kết từ đâu đó.
Tương tự như vậy, trong một trang web thương mại điện tử, bạn có thể có các bộ lọc khía cạnh tạo ra các URL như /?color=red&size=s.
Các tham số chuỗi truy vấn này có thể tạo ra vô số kết hợp URL duy nhất mà Google có thể thử thu thập.
Về cơ bản, các URL đó không có nội dung độc đáo và chỉ lọc dữ liệu bạn có, điều này rất tốt cho trải nghiệm của người dùng nhưng lại không tốt cho Googlebot.
Cho phép Google thu thập các URL này sẽ lãng phí ngân sách thu thập và ảnh hưởng đến khả năng thu thập tổng thể của trang web của bạn. Bằng cách chặn chúng thông qua các quy tắc robots.txt , Google sẽ tập trung nỗ lực thu thập dữ liệu vào các trang hữu ích hơn trên trang web của bạn.
Sau đây là cách chặn tìm kiếm nội bộ, khía cạnh hoặc bất kỳ URL nào chứa chuỗi truy vấn thông qua robots.txt:
Disallow: *?*s=*
Disallow: *?*color=*
Disallow: *?*size=*
Mỗi quy tắc không cho phép bất kỳ URL nào chứa tham số truy vấn tương ứng, bất kể có tham số nào khác có thể có.
* (dấu sao) khớp với bất kỳ chuỗi ký tự nào (bao gồm cả không có ký tự nào).
? (Dấu chấm hỏi): Biểu thị sự bắt đầu của chuỗi truy vấn.
=*: Phù hợp với dấu = và bất kỳ ký tự nào theo sau.
Cách tiếp cận này giúp tránh sự trùng lặp và đảm bảo rằng các URL có các tham số truy vấn cụ thể này sẽ không bị các công cụ tìm kiếm thu thập thông tin.
Tuy nhiên, lưu ý rằng phương pháp này đảm bảo bất kỳ URL nào chứa các ký tự được chỉ định sẽ không được phép bất kể các ký tự đó xuất hiện ở đâu. Điều này có thể dẫn đến việc không được phép ngoài ý muốn. Ví dụ, các tham số truy vấn chứa một ký tự duy nhất sẽ không cho phép bất kỳ URL nào chứa ký tự đó bất kể nó xuất hiện ở đâu. Nếu bạn không cho phép 's', các URL chứa '/?pages=2' sẽ bị chặn vì *?*s= cũng khớp với '?pages='. Nếu bạn muốn không cho phép các URL có một ký tự duy nhất cụ thể, bạn có thể sử dụng kết hợp các quy tắc:
Disallow: *?s=*
Disallow: *&s=*
Thay đổi quan trọng là không có dấu sao '*' giữa các ký tự '?' và 's'. Phương pháp này cho phép bạn không cho phép các tham số 's' cụ thể trong URL, nhưng bạn sẽ cần thêm từng biến thể riêng lẻ.
Áp dụng các quy tắc này cho các trường hợp sử dụng cụ thể của bạn đối với bất kỳ URL nào không cung cấp nội dung duy nhất. Ví dụ: trong trường hợp bạn có các nút danh sách mong muốn với URL “?add_to_wishlist=1”, bạn cần không cho phép chúng theo quy tắc:
Disallow: /*?*add_to_wishlist=*
Đây là bước đầu tiên và quan trọng nhất mà Google khuyến nghị, điều này hiển nhiên và dễ hiểu .
Một ví dụ bên dưới cho thấy cách chặn các tham số đó giúp giảm việc thu thập dữ liệu các trang có chuỗi truy vấn. Google đã cố gắng thu thập dữ liệu hàng chục nghìn URL có các giá trị tham số khác nhau không có ý nghĩa, dẫn đến các trang không tồn tại .
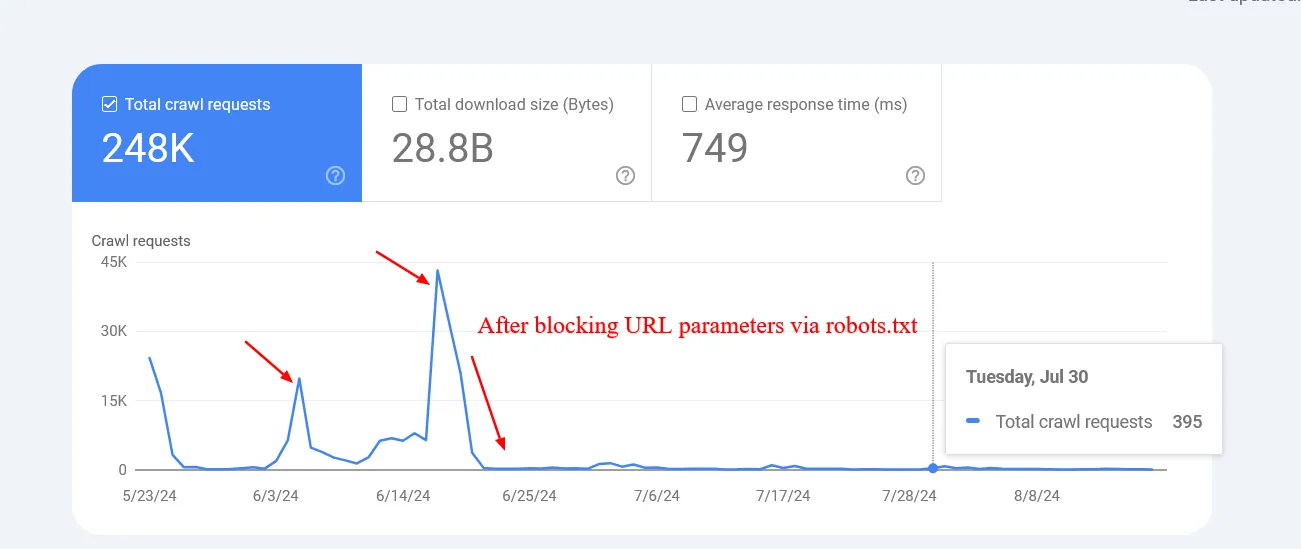
Giảm tốc độ thu thập dữ liệu của các URL có tham số sau khi chặn thông qua robots.txt.
Tuy nhiên, đôi khi các URL không được phép vẫn có thể được thu thập và lập chỉ mục bởi các công cụ tìm kiếm. Điều này có vẻ lạ, nhưng nhìn chung không đáng báo động. Điều này thường có nghĩa là các trang web khác liên kết đến các URL đó.
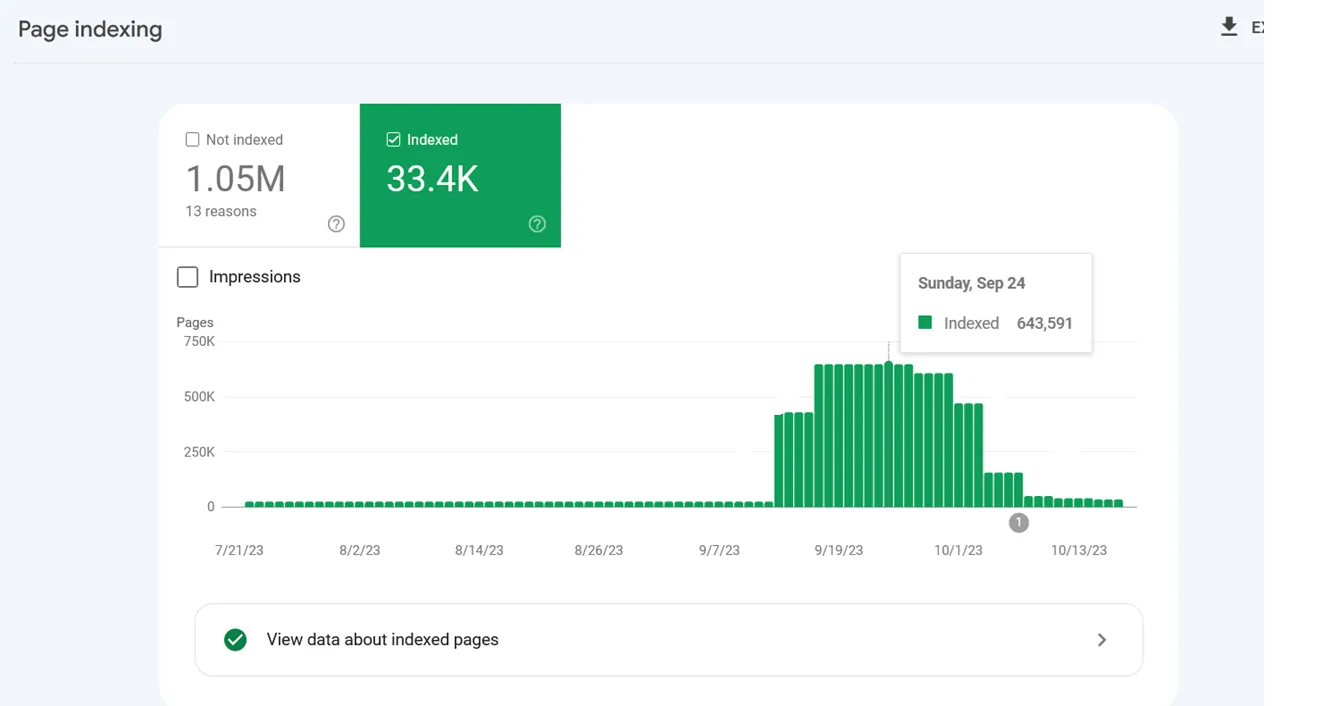
Việc lập chỉ mục tăng đột biến vì Google lập chỉ mục các URL tìm kiếm nội bộ sau khi chúng bị chặn thông qua robots.txt.
Google xác nhận rằng hoạt động thu thập dữ liệu sẽ giảm dần theo thời gian trong những trường hợp này.
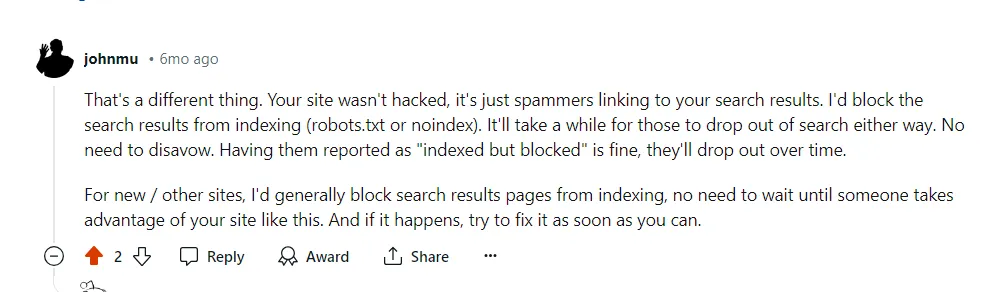
Bình luận của Google về Reddit, tháng 7 năm 2024
Một lợi ích quan trọng khác của việc chặn các URL này thông qua robots.txt là tiết kiệm tài nguyên máy chủ của bạn. Khi một URL chứa các tham số cho biết sự hiện diện của nội dung động, các yêu cầu sẽ được chuyển đến máy chủ thay vì bộ nhớ đệm . Điều này làm tăng tải trên máy chủ của bạn với mỗi trang được thu thập.
Xin hãy nhớ không sử dụng “ thẻ meta noindex ” để chặn vì Googlebot phải thực hiện yêu cầu để xem thẻ meta hoặc mã phản hồi HTTP, gây lãng phí ngân sách thu thập thông tin.
Bên cạnh việc không cho phép URL hành động, bạn có thể không cho phép các tệp JavaScript không phải là một phần của bố cục hoặc kết xuất trang web.
Ví dụ, nếu bạn có các tệp JavaScript chịu trách nhiệm mở hình ảnh trong cửa sổ bật lên khi người dùng nhấp vào, bạn có thể không cho phép chúng trong robots.txt để Google không lãng phí ngân sách vào việc thu thập dữ liệu.
Sau đây là một ví dụ về quy tắc không cho phép của tệp JavaScript:
Disallow: /assets/js/popup.js
Tuy nhiên, bạn không bao giờ nên từ chối các tài nguyên là một phần của quá trình kết xuất. Ví dụ: nếu nội dung của bạn được tải động thông qua JavaScript, Google cần thu thập dữ liệu các tệp JS để lập chỉ mục nội dung mà chúng tải.
Một ví dụ khác là các điểm cuối REST API cho việc gửi biểu mẫu. Giả sử bạn có một biểu mẫu với URL hành động “/rest-api/form-submissions/”.
Có khả năng Google có thể thu thập chúng. Các URL đó không liên quan gì đến việc hiển thị và sẽ là một biện pháp tốt nếu chặn chúng.
Disallow: /rest-api/form-submissions/
Tuy nhiên, CMS không có giao diện người dùng thường sử dụng REST API để tải nội dung động, vì vậy hãy đảm bảo bạn không chặn các điểm cuối đó.
Nói tóm lại, hãy xem bất cứ thứ gì không liên quan đến việc kết xuất và chặn chúng.
Chuỗi chuyển hướng xảy ra khi nhiều URL chuyển hướng đến các URL khác cũng chuyển hướng. Nếu điều này diễn ra quá lâu, trình thu thập thông tin có thể từ bỏ chuỗi trước khi đến đích cuối cùng.
URL 1 chuyển hướng đến URL 2, URL 2 lại chuyển hướng đến URL 3, v.v. Chuỗi cũng có thể có dạng vòng lặp vô hạn khi các URL chuyển hướng đến nhau.
Tránh những lỗi này là cách tiếp cận hợp lý để bảo vệ sức khỏe của trang web.
Trong trường hợp lý tưởng, bạn có thể tránh được việc có ngay cả một chuỗi chuyển hướng duy nhất trên toàn bộ tên miền của mình.
Nhưng đây có thể là nhiệm vụ bất khả thi đối với một trang web lớn – chuyển hướng 301 và 302 chắc chắn sẽ xuất hiện và bạn không thể sửa lỗi chuyển hướng từ các liên kết ngược chỉ vì bạn không kiểm soát được các trang web bên ngoài.
Một hoặc hai lần chuyển hướng ở đây và ở đó có thể không gây hại nhiều, nhưng các chuỗi và vòng lặp dài có thể gây ra vấn đề.
Để khắc phục sự cố chuỗi chuyển hướng, bạn có thể sử dụng một trong các công cụ SEO như Screaming Frog, Lumar hoặc Oncrawl để tìm chuỗi.
Khi bạn phát hiện ra một chuỗi, cách tốt nhất để sửa nó là xóa tất cả các URL giữa trang đầu tiên và trang cuối cùng. Nếu bạn có một chuỗi đi qua bảy trang, hãy chuyển hướng URL đầu tiên trực tiếp đến trang thứ bảy.
Một cách tuyệt vời khác để giảm chuỗi chuyển hướng là thay thế các URL nội bộ chuyển hướng bằng đích đến cuối cùng trong CMS của bạn.
Tùy thuộc vào CMS của bạn, có thể có các giải pháp khác nhau; ví dụ, bạn có thể sử dụng plugin này cho WordPress. Nếu bạn có CMS khác, bạn có thể cần sử dụng giải pháp tùy chỉnh hoặc yêu cầu nhóm phát triển của bạn thực hiện.
Bây giờ, nếu chúng ta đang nói về Google, trình thu thập thông tin của họ sử dụng phiên bản Chrome mới nhất và có thể thấy nội dung được tải bằng JavaScript một cách tốt.
Nhưng hãy suy nghĩ một cách phê phán. Điều đó có nghĩa là gì? Googlebot thu thập dữ liệu một trang và các tài nguyên như JavaScript sau đó sử dụng nhiều tài nguyên tính toán hơn để hiển thị chúng.
Hãy nhớ rằng chi phí tính toán rất quan trọng đối với Google và họ muốn giảm chi phí này càng nhiều càng tốt.
Vậy tại sao lại hiển thị nội dung thông qua JavaScript ( phía máy khách ) và làm tăng thêm chi phí tính toán cho Google để thu thập dữ liệu trang của bạn?
Vì vậy, nếu có thể, bạn nên sử dụng HTML.
Bằng cách đó, bạn sẽ không làm mất đi cơ hội của mình với bất kỳ trình thu thập thông tin nào.
Như đã thảo luận ở trên, Googlebot thu thập và hiển thị các trang bằng JavaScript, nghĩa là nếu Googlebot sử dụng ít tài nguyên hơn để hiển thị các trang web thì việc thu thập sẽ dễ dàng hơn, tùy thuộc vào mức độ tối ưu hóa tốc độ trang web của bạn .
Google cho biết :
Việc thu thập dữ liệu của Google bị giới hạn bởi băng thông, thời gian và tính khả dụng của các phiên bản Googlebot. Nếu máy chủ của bạn phản hồi yêu cầu nhanh hơn, chúng tôi có thể thu thập nhiều trang hơn trên trang web của bạn.
Vì vậy, sử dụng kết xuất phía máy chủ đã là một bước tiến tuyệt vời để cải thiện tốc độ trang, nhưng bạn cần đảm bảo các số liệu Core Web Vital của mình được tối ưu hóa, đặc biệt là thời gian phản hồi của máy chủ.
Google thu thập các URL có trên trang và luôn lưu ý rằng các URL khác nhau sẽ được trình thu thập tính là các trang riêng biệt.
Nếu bạn có trang web có phiên bản 'www', hãy đảm bảo các URL nội bộ, đặc biệt là trên thanh điều hướng, trỏ đến phiên bản chuẩn, tức là phiên bản 'www' và ngược lại.
Một lỗi phổ biến khác là thiếu dấu gạch chéo ở cuối. Nếu URL của bạn có dấu gạch chéo ở cuối, hãy đảm bảo URL nội bộ của bạn cũng có dấu gạch chéo.
Nếu không, các chuyển hướng không cần thiết, ví dụ: “https://www.example.com/sample-page” đến “https://www.example.com/sample-page/” sẽ dẫn đến hai lần thu thập dữ liệu cho mỗi URL.
Một khía cạnh quan trọng khác là tránh các trang liên kết nội bộ bị hỏng , có thể làm tốn ngân sách thu thập thông tin và các trang 404 mềm .
Và tệ hơn nữa, chúng còn làm tổn hại đến trải nghiệm người dùng của bạn!
Trong trường hợp này, một lần nữa, tôi ủng hộ việc sử dụng công cụ để kiểm tra trang web.
WebSite Auditor, Screaming Frog, Lumar hoặc Oncrawl và SE Ranking là những ví dụ về các công cụ tuyệt vời để kiểm tra trang web .
Một lần nữa, việc chăm sóc sơ đồ trang web XML thực sự mang lại lợi ích cho cả hai bên.
Các bot sẽ hiểu rõ hơn và dễ dàng hơn về nơi các liên kết nội bộ dẫn đến.
Chỉ sử dụng các URL chuẩn cho sơ đồ trang web của bạn.
Ngoài ra, hãy đảm bảo rằng nó tương ứng với phiên bản mới nhất của robots.txt và tải nhanh.
Khi thu thập dữ liệu từ một URL, Googlebot sẽ gửi một ngày thông qua tiêu đề “ If-Modified-Since ”, đây là thông tin bổ sung về lần cuối cùng Googlebot thu thập dữ liệu từ URL đã cho.
Nếu trang web của bạn không thay đổi kể từ đó (được chỉ định trong “ If-Modified-Since “), bạn có thể trả về mã trạng thái “304 Not Modified” mà không có nội dung phản hồi. Điều này cho các công cụ tìm kiếm biết rằng nội dung trang web không thay đổi và Googlebot có thể sử dụng phiên bản từ lần truy cập cuối cùng trên tệp.
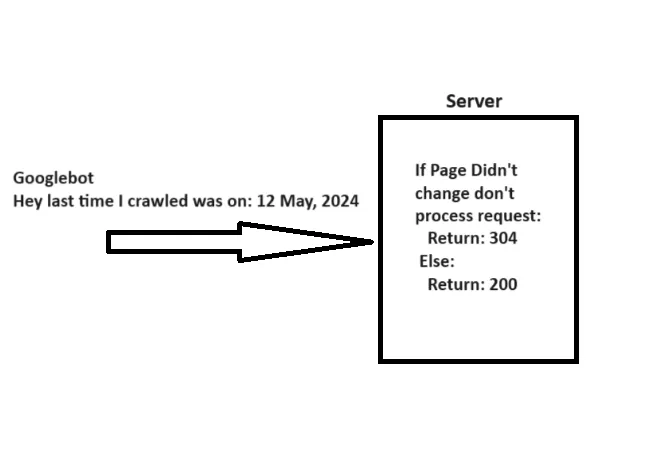
Giải thích đơn giản về cách hoạt động của mã trạng thái http 304 không được sửa đổi.
Hãy tưởng tượng bạn có thể tiết kiệm được bao nhiêu tài nguyên máy chủ khi giúp Googlebot tiết kiệm tài nguyên khi bạn có hàng triệu trang web. Khá lớn phải không?
Tuy nhiên, có một lưu ý khi triển khai mã trạng thái 304, được Gary Illyes chỉ ra .
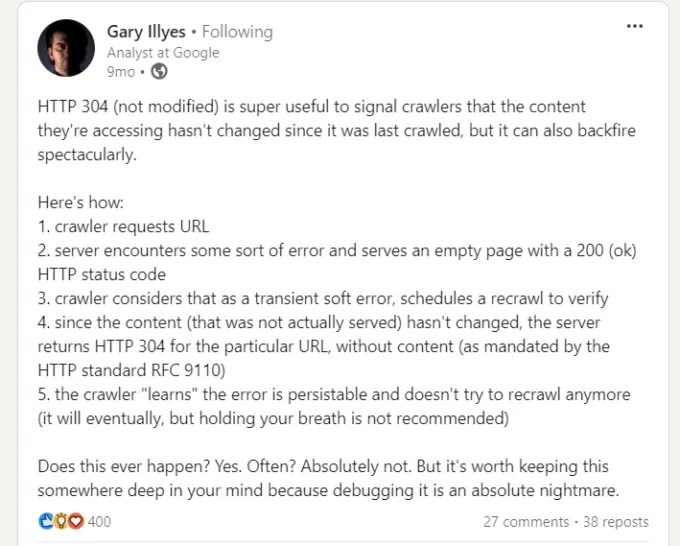
Gary Illes trên LinkedIn
Vì vậy, hãy thận trọng. Lỗi máy chủ cung cấp các trang trống có trạng thái 200 có thể khiến trình thu thập dữ liệu ngừng thu thập lại, dẫn đến các vấn đề lập chỉ mục kéo dài.
Để phân tích các trang bản địa hóa của bạn, trình thu thập thông tin sử dụng thẻ hreflang. Bạn nên cho Google biết về các phiên bản bản địa hóa của các trang của bạn một cách rõ ràng nhất có thể.
Trước tiên, hãy sử dụng trong tiêu đề trang của bạn. Trong đó “lang_code” là mã cho ngôn ngữ được hỗ trợ .lang_code" href="url_of_page" />
Bạn nên sử dụng phần tử
Kiểm tra nhật ký máy chủ và báo cáo Thống kê thu thập dữ liệu của Google Search Console để theo dõi các bất thường khi thu thập dữ liệu và xác định các vấn đề tiềm ẩn.
Nếu bạn nhận thấy các trang 404 thỉnh thoảng xuất hiện, trong 99% trường hợp, nguyên nhân là do không gian thu thập dữ liệu vô hạn , điều mà chúng tôi đã thảo luận ở trên, hoặc chỉ ra các vấn đề khác mà trang web của bạn có thể đang gặp phải.
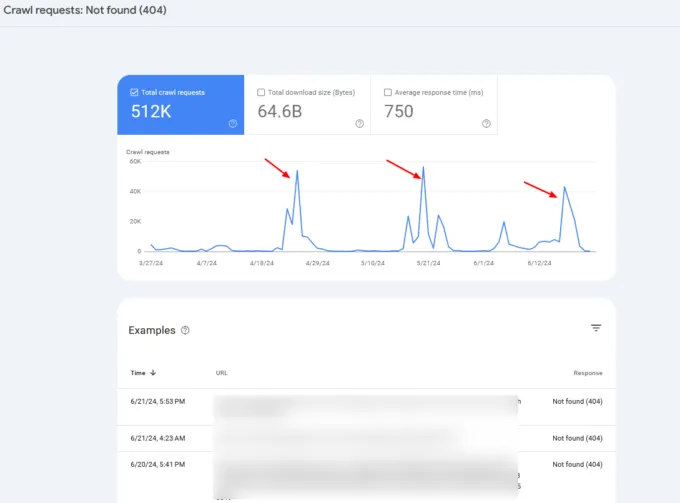
Tốc độ thu thập dữ liệu tăng đột biến
Thông thường, bạn có thể muốn kết hợp thông tin nhật ký máy chủ với dữ liệu Search Console để xác định nguyên nhân gốc rễ.
Vì vậy, nếu bạn đang thắc mắc liệu việc tối ưu hóa ngân sách thu thập dữ liệu có còn quan trọng đối với trang web của mình hay không thì câu trả lời rõ ràng là CÓ .
Ngân sách thu thập dữ liệu là, đã và có thể sẽ là một điều quan trọng mà mọi chuyên gia SEO cần ghi nhớ.
Hy vọng những mẹo này sẽ giúp bạn tối ưu hóa ngân sách thu thập dữ liệu và cải thiện hiệu suất SEO – nhưng hãy nhớ rằng, việc thu thập dữ liệu trên các trang của bạn không có nghĩa là chúng sẽ được lập chỉ mục.



Cảm ơn bạn đã quan tâm. Chúng tôi sẽ liên hệ lại với bạn trong thời gian sớm nhất.
Gửi thông tin thành công





